:question::warning::boom: work in progress :construction::zap::exclamation:
What is this? Why?
The goal is to use data from govtrack.us and some fancy d3js visualizations to create a multi-device, collaborative environment that allows for exploration and discovery inside a large (publicly available) dataset.
This project tries to both explore new/novel data visualizations and interactions as well as expose already available data to provide actionable insights and increased transparency in government.
This work is currently in progress at the Information Interfaces Lab in the GVU Center at Georgia Tech.
What are you using?
So far:
- Elasticsearch for text search
- MySQL for everything else
- Node.js and Express.js framework
- Backbone.js for the client-side web
- d3js to do some neat visualizations
- miscellaneous python scripts to pre-process and bulk import data
Eventually:
- probably Firebase to facilitate easy real-time communications/collaboration between multiple devices
Getting Started
Note: The brew command refers to homebrew a package manager
for Mac OS X. Either replace with the proper package manager for your operating
system (e.g. apt-get for Ubuntu) or install from official binaries.
Install Node.js, MySQL and Elasticsearch
brew install node brew install mysql # this takes a while brew install elasticsearch- Consider installing MySQL Workbench as an alternative to using the command line interface for MySQL
Clone this repo
git clone [email protected]:BunsenMcDubbs/congressvis.git cd congressvisSetup datastores
Download data from GovTrack into the
data/directory (see more details in the README there).cd data rsync -avz --delete govtrack.us::govtrackdata/congress/113/ . rsync -avz --delete govtrack.us::govtrackdata/congress-legislators/* membership rsync -avz govtrack.us::govtrackdata/us/sessions.tsv . rsync -avz --delete govtrack.us::govtrackdata/us/liv111.xml subjects/ rsync -avz --delete govtrack.us::govtrackdata/us/crsnet.xml subjects/Setup MySQL and import the schema from
data/utils/congressvis_schema.sqlUse
data/utils/mysql_import.pyto import data into MySQL (see documentation by runningpython data/utils/mysql_import.py -hand refer to README in data folder)# in a new (second) terminal window elasticsearch # start elasticsearch # back in the first one: cd .. # come back up to project root python data/utils/mysql_import.py -u <USERNAME> -p <PASSWORD> -db <DATABASE> --path data/ # once the importing is finished you can stop elasticsearch with Ctrl-C # and close the second window
Install project dependencies
# at the project root npm install npm install -g bower bower installCopy
config-example.jstoconfig.jsand fill in with the proper credentialscp config-example.js config.js # edit config.jsStart the server
npm start # which runs the script bin/www - see package.json for more detailsNow the server should be running on localhost:3000. Navigate to http://localhost:3000 in your favorite web browser to confirm.
Note: MySQL and Elasticsearch must be running for all parts to work
???
Congrats.

API Documentation
Source Documentation
Project Layout/Filesystem Overview
Note: This project layout was initially generated with the
express-generator
and mostly follows standard Express.js conventions.
Directories
data/raw data from govtrack (see README there)data/utils/python scripts to quickly import data files into MySQL
api/handlers and converters that talk with the database (ORM-esque)public/(static) client-side resourcespublic/style-> stylesheetspublic/scripts-> client-side javascript ex) Backbone application, d3js visualizations
routes/express routers (and a bit of database connection logic)views/view templates (handlebars) that are (mostly) rendered server-side
Files of Interest
bin/wwwnode server startup script- can be called with either
npm start(recommended) or./bin/wwwfrom project root
- can be called with either
config.jsdeployment specific settings and sensitive information (credentials etc.)app.js
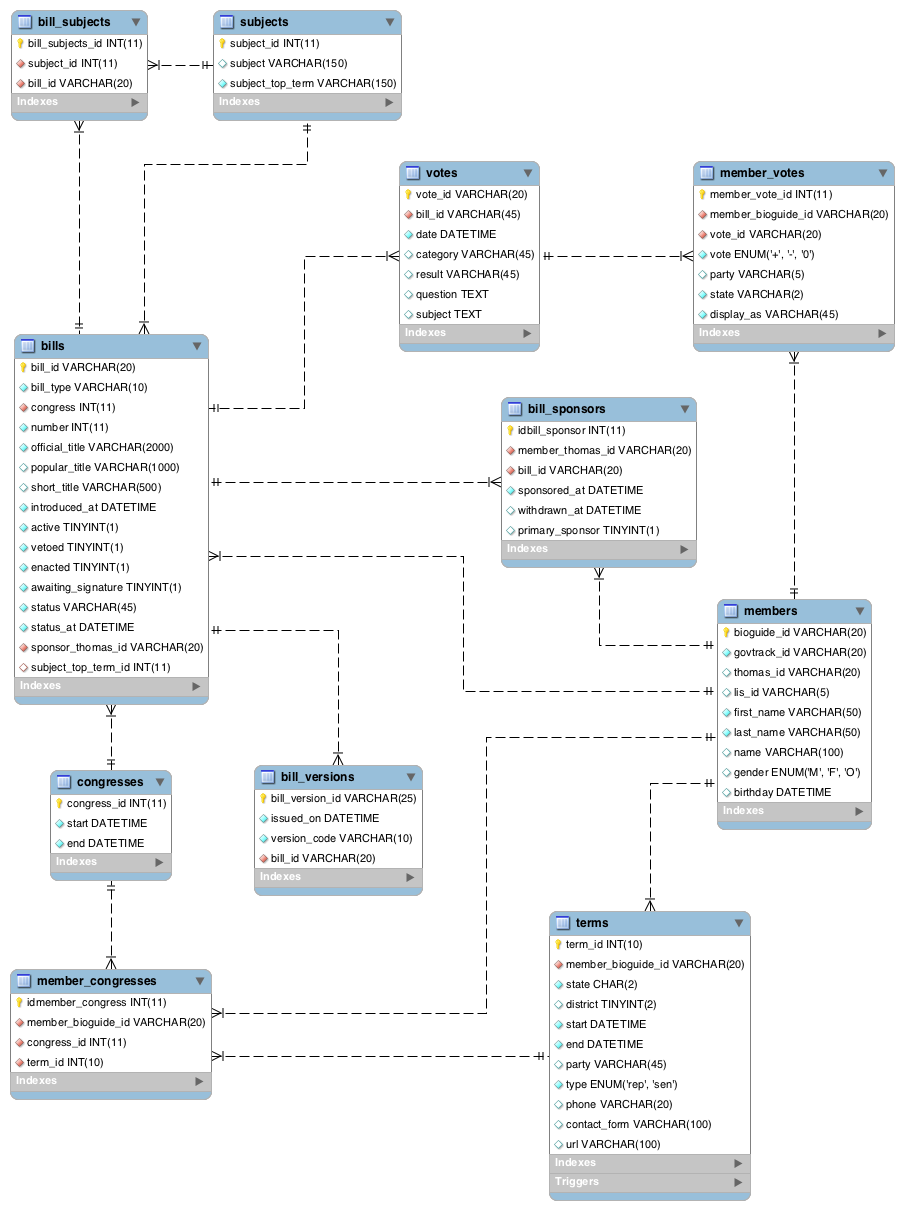
Database Schema
Todo: written documentation for database schema